Le terminal est idéal pour exécuter des tâches, et l’une des tâches qui, à mon avis, est plus rapide à effectuer dans le terminal que dans l’interface utilisateur graphique est la recherche basée sur le terminal. En utilisant plusieurs commandes Linux, vous pouvez facilement et rapidement trouver n’importe quoi sans fouiller dans les fichiers et les dossiers dans un gestionnaire de fichiers GUI. Voyons comment effectuer une recherche dans le terminal Linux et trouver ce que vous cherchez.
Recherche de texte dans des fichiers avec grep
Si vous n’apprenez qu’une seule commande de recherche, faites-la grep. Le nom signifie Global Regular Expression Print, et son travail est simple : rechercher dans les fichiers des modèles de texte spécifiques. Il est installé par défaut sur la plupart des systèmes Linux (et macOS).
La syntaxe est simple, il vous suffit d’utiliser grep avec le modèle de recherche souhaité. Par exemple, disons que vous essayez de trouver chaque ligne mentionnant une erreur dans un fichier. Vous pouvez le faire avec :
grep "error" fileserver.logIl imprime chaque ligne contenant le mot erreur. Si vous souhaitez qu’il ignore la casse (pour qu’il corresponde à Error, ERROR, etc.), ajoutez simplement le -i drapeau comme ceci :
grep -i "error" fileserver.logSi vous n’êtes pas sûr de l’emplacement du fichier et que vous souhaitez effectuer une recherche dans un répertoire entier, utilisez l’option -r option (récursive):
grep -r "TODO"Cela parcourt chaque fichier du dossier actuel et de tous les sous-dossiers, à la recherche du mot « TODO ».
Parfois, vous voulez tout voir sauf votre terme de recherche. Le -v flag inverse la recherche, affichant uniquement les lignes qui ne correspondent pas. C’est fantastique pour filtrer le bruit des fichiers journaux.
grep -v "DEBUG" app.logCela me montre tout ce qui n’est pas un message de débogage.
Combiner grep avec d’autres commandes
Vous pouvez également combiner grep avec d’autres commandes. Par exemple, vous pouvez canaliser (en utilisant le | symbole) la sortie d’une commande directement dans une autre. Cela vous permet d’enchaîner des commandes. Supposons que vous souhaitiez voir tous les processus SSH exécutés sur votre système. Vous pouvez lister tous les processus, puis diriger cette liste géante vers grep en utilisant ceci :
ps aux | grep "ssh"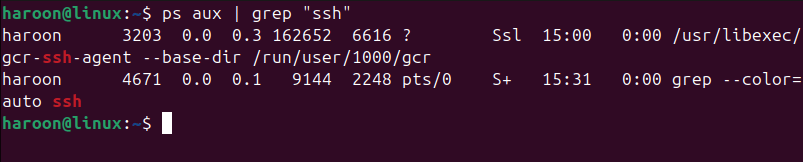
Le ps aux La commande peut répertorier 300 processus, mais grep le filtre jusqu’à celui ou deux qui vous intéressent réellement. Vous pouvez l’utiliser pour n’importe quoi.
grep prend également en charge les expressions régulières, pour des modèles plus avancés. Vous pouvez rechercher des éléments tels que n’importe quelle ligne commençant par un numéro, ou des adresses e-mail ou des numéros de téléphone dans un format spécifique. Par exemple, pour rechercher des lignes commençant par un nombre, utilisez ceci :
grep "^(0-9)" file.txtLa courbe d’apprentissage devient ici plus abrupte, mais les bénéfices sont énormes.
grep vs ripgrep : quelle est la différence et lequel utiliser
Vous savez déjà à quel point grep est utile pour rechercher du texte dans des fichiers, mais il existe une alternative plus rapide et plus moderne appelée ripgrep (rg). Il fonctionne presque de la même manière que grep mais offre de bien meilleures performances et des paramètres par défaut plus pratiques.
La principale différence est la vitesse. Alors que grep traite les fichiers de manière séquentielle, ripgrep inclut des optimisations (y compris le multithreading et l’ignorance des fichiers non pertinents) qui le rendent souvent beaucoup plus rapide. Sur les grands projets, une recherche qui peut prendre 30 secondes peut se terminer en moins d’une seconde avec ripgrep. Il est écrit en Rust et optimisé pour gérer efficacement de grands répertoires.
Contrairement à grep, ripgrep n’est pas installé par défaut. Vous devez l’installer sur votre système à l’aide de votre gestionnaire de packages. Par exemple, sur Ubuntu/Debian, utilisez ceci :
sudo apt install ripgrepUne fois installé, vous l’utiliserez presque exactement comme grep :
rg "TODO"
Cette commande recherche tous les fichiers du dossier actuel et de ses sous-dossiers. ripgrep ignore automatiquement les fichiers cachés, les répertoires .git et les fichiers binaires, de sorte que vous ne voyez que les résultats pertinents. Il affiche également les numéros de ligne et les surlignages colorés par défaut.
En bref, les deux outils font le même travail, mais ripgrep est plus rapide et plus pratique pour une utilisation quotidienne, notamment lors de la recherche de grands projets. Cependant, grep reste utile lorsque vous êtes sur des systèmes sur lesquels vous ne pouvez pas installer de nouveaux logiciels ou lorsque vous avez besoin d’un outil disponible partout par défaut.
Recherche de fichiers et de répertoires avec find
Alors que grep vous aide à rechercher dans les fichiers, la commande find vous aide à localiser les fichiers et les dossiers eux-mêmes. C’est l’outil à utiliser lorsque vous connaissez le nom ou le type de ce que vous recherchez, mais pas l’endroit où il est stocké. Vous pouvez effectuer une recherche par nom, taille, heure de modification, autorisations, type de fichier, à peu près n’importe quel attribut auquel vous pouvez penser.
La syntaxe de base ressemble à ceci :
find /path -name "filename"Cette commande indique à find de commencer la recherche à partir du chemin donné et de rechercher les fichiers correspondant au nom spécifié. Par exemple, si vous essayez de retrouver un fichier de configuration manquant, exécutez :
find /etc -name "config.json"Par défaut, -name est sensible à la casse. Si vous n’êtes pas sûr de la capitalisation, passez à -iname pour une recherche insensible à la casse :
find . -iname "readme.md"Le point (.) signifie démarrer dans le répertoire courant. find peut faire bien plus que de simples recherches basées sur le nom. Vous pouvez filtrer les résultats en fonction de la dernière modification des fichiers, ce qui est pratique lors du nettoyage des journaux ou des sauvegardes. Par exemple, cette commande répertorie tous les fichiers journaux modifiés au cours des trois derniers jours :
find /var/log -name "*.log" -mtime -3L’astérisque agit comme un caractère générique, correspondant à n’importe quel caractère. Vous pouvez également l’utiliser pour rechercher des fichiers volumineux susceptibles de remplir votre espace disque.
Recherche interactive avec fzf
fzf signifie Fuzzy Finder, et il s’agit essentiellement d’un outil de recherche interactif pour votre terminal. C’est un filtre flou dans lequel vous pouvez canaliser des éléments. Il vous offre une sortie ultra-rapide, au fur et à mesure que vous tapez, dans la barre de recherche pour n’importe quelle liste. Vous n’avez pas non plus besoin d’être précis, si vous recherchez « react_component.js », vous pouvez simplement taper rctjs et fzf comprendra ce que tu veux dire.
Pour l’utiliser, vous devez l’installer sur votre système à l’aide de votre gestionnaire de packages. Sur Ubuntu/Debian, exécutez ceci :
sudo apt install fzfUne fois installé, le moyen le plus simple d’utiliser fzf est simplement de taper :
fzf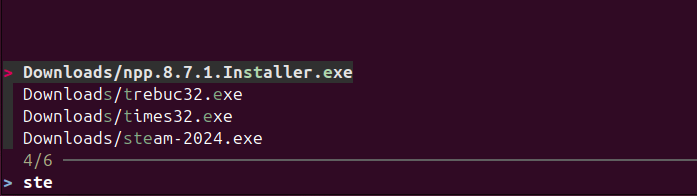
Vous obtiendrez instantanément une liste consultable des fichiers dans votre dossier actuel. Au fur et à mesure que vous tapez, il filtre les résultats en temps réel. Vous pouvez naviguer avec les touches fléchées et appuyer sur Entrée pour en sélectionner une.
Vous pouvez également le combiner avec find. Par exemple:
find . -type f | fzfCela vous permettra de choisir un fichier de manière interactive dans la liste générée par find.
Vous pouvez même l’utiliser pour rechercher votre historique de commandes :
history | fzfCela vous permet de rechercher de manière interactive votre historique de commandes. Vous pouvez facilement retrouver la commande que vous avez exécutée il y a trois jours, mais vous ne vous en souvenez plus vraiment. Tapez quelques lettres, trouvez-le, appuyez sur Entrée et il est prêt à fonctionner.
Filtrage intelligent des fichiers avec accusé de réception
ack est similaire à grep, mais il est spécialement conçu pour la recherche dans le code. Il ignore automatiquement les fichiers non pertinents (comme les binaires, les journaux ou les dossiers de contrôle de version), ce qui le rend parfait pour les développeurs. Il n’est pas disponible par défaut, vous devez l’installer sur votre système. Par exemple, si vous utilisez Ubuntu, exécutez ceci :
sudo apt install ackUne fois installé, vous pouvez l’utiliser pour rechercher n’importe quoi. Par exemple, pour rechercher une définition de fonction dans des fichiers Python, utilisez :
ack --python "def my_function"Vous voulez trouver tous les commentaires TODO de votre projet ? Courir:
ack "TODO"Vous pouvez également l’utiliser avec des indicateurs courants, par exemple, si vous avez besoin d’une recherche insensible à la casse avec des numéros de ligne, exécutez :
ack -i -n "config"De plus, ack connaît déjà les types de fichiers courants. Vous pouvez effectuer une recherche uniquement dans les fichiers JavaScript, les fichiers Python ou les fichiers Markdown à l’aide d’indicateurs tels que --js ou --python.
À l’époque, avant l’arrivée de ripgrep, ack était l’outil incontournable des développeurs. Désormais, ripgrep est plus rapide, mais ack a toujours son charme pour une sortie lisible et un filtrage convivial pour les développeurs.
Pensées finales
Le terminal Linux peut sembler intimidant au début, mais une fois que vous commencez à utiliser ces outils de recherche, il devient une partie de votre flux de travail quotidien. Une fois que vous êtes à l’aise avec eux, vous pouvez également créer des alias dans votre shell afin de ne pas avoir à mémoriser de longues commandes.